
openVPS: Poor man’s motion capture
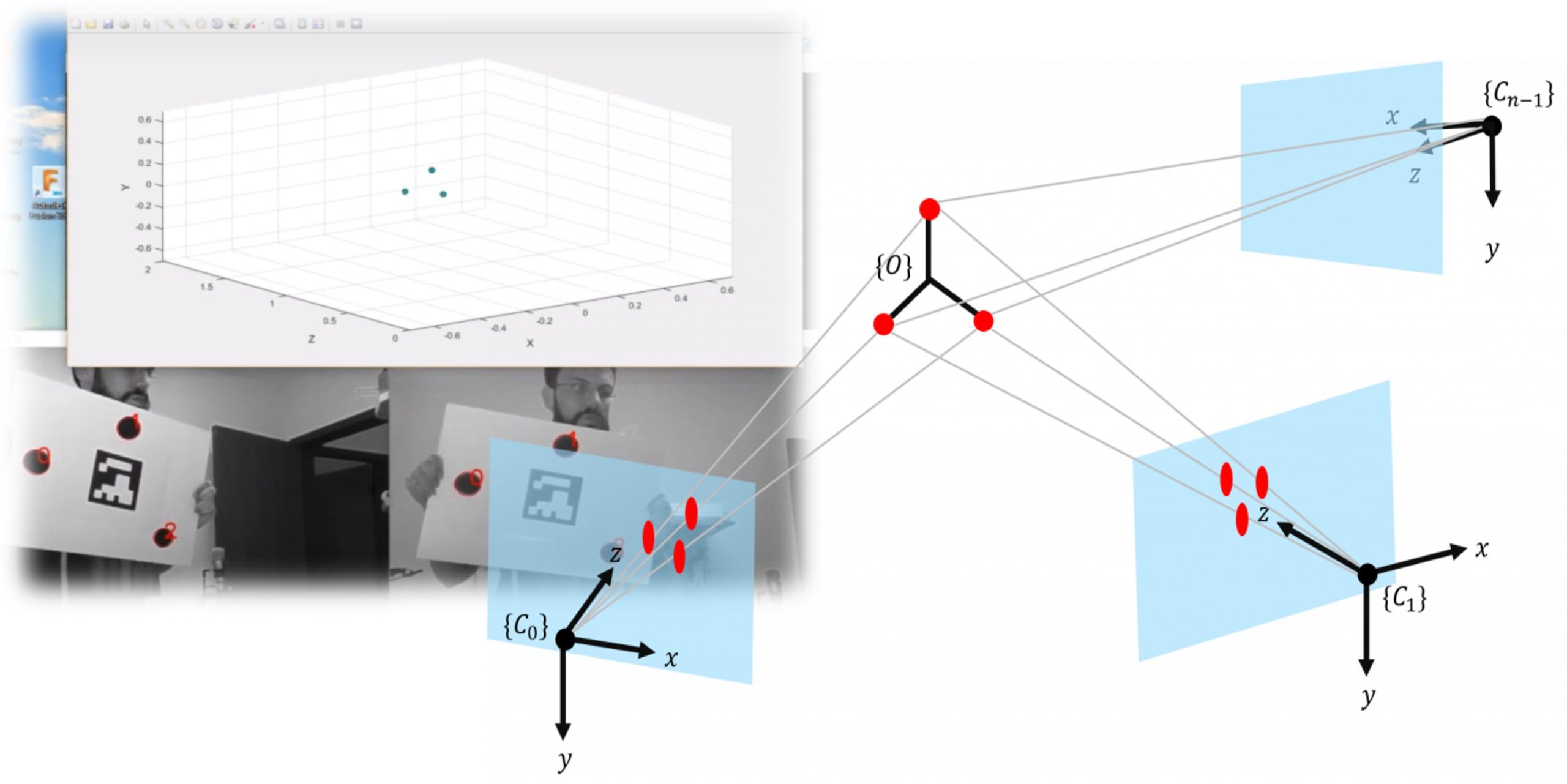
The Why and The What Flying tiny drones indoors is cool, no questions asked. And stuff gets all the more interesting when you can accurately control the drone’s position in space — enabling all sort of crazy manouvers. However, using regular GPS for such applications is often a no-go: antennas may be too heavy for the … Read more